Makine öğrenmesi, insanların öğrenme şeklini tahmin etmek için verilerin ve algoritmaların ortak kullanımına odaklanan bir yapay zeka ve bilgisayar bilimi dalıdır. Bu bilim dalı için veri setlerini bir modele dönüştürme amacıyla en uygun algoritmayı seçmek her zaman önemlidir. Bu yazıda yaygın kullanılan makine öğrenimi algoritmalarının avantajlarını ve dezavantajlarını inceleyeceğiz.
Makine Öğrenimi Algoritmaları: Avantajları ve Dezavantajları
Makine Öğrenimi Algoritmaları
Doğrusal ( Lineer ) Regresyon

Avantajları;
- Uygulaması basit olmakla birlikte eğitilmesi verimli.
- Regularization teknikleri kullanılarak aşırı öğrenmenin önüne geçilebilir.
- Veri seti doğrusal özellik gösterdiğinde iyi performans verir.
Dezavantajları;
- Verilerin bağımsız olduğunu varsayar ancak gerçek hayatta bu durum nadirdir.
- Aşırı öğrenmeye ve gürültüye (noise) eğilimlidir.
- Aykırı değerlere (outliers) duyarlıdır.
Lojistik Regresyon
Avantajları;
- Aşırı öğrenmeye daha az eğilimlidir, ancak büyük boyutlu veri kümelerinde aşırı öğrenmeye eğilim artar.
- Veri kümesi doğrusal olarak ayrılabilir özelliklere sahip olduğunda etkilidir.
- Uygulaması kolaydır ve eğitilmesi verimlidir.
Dezavantajları;
- Gözlem sayısı öznitelik sayısından az olduğunda kullanılmamalıdır.
- Doğrusallık varsayımı uygulamada nadir görülür.
- Yalnızca ayrık fonksiyonları tahminleme için kullanılabilir.
Destek Vektör Makinesi
Avantajları;
- Büyük boyutlu veri setlerinde performansı iyidir.
- Küçük veri seti üzerinde çalışabilir.
- Doğrusal olmayan problemleri çözebilir.
Dezavantajları;
- Büyük veri setlerinde verimsizdir.
- Çakışan sınıflarla kötü çalışır.
- Kullanılan çekirdek türüne duyarlıdır.
Karar Ağacı
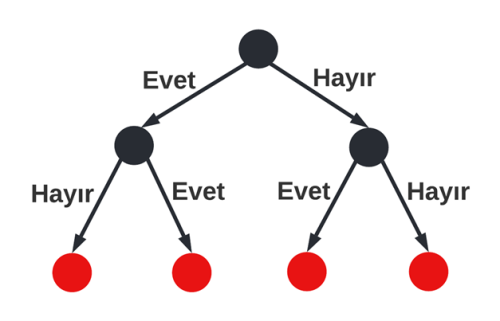
Avantajları;
- Lineer olmayan problemleri çözebilir.
- Büyük boyutlu veriler üzerinde mükemmel doğrulukla (accuracy) çalışabilir.
- Görselleştirmesi ve açıklaması kolaydır.
Dezavantajları;
- Aşırı öğrenmeye sebep olur. Rastgele orman ile çözülebilir.
- Verilerdeki küçük bir değişiklik, optimal karar ağacının yapısında büyük bir değişikliğe yol açabilir.
- Hesaplamalar çok karmaşık olabilir.
K-En Yakın Komşu Algoritması

Avantajları;
- Eğitim almadan tahmin yapabilir.
- Zaman karmaşıklığı O(n)’dir.
- Hem sınıflandırma hem de regresyon için kullanılabilir.
- Uygulaması kolaydır.
Dezavantajları;
- Büyük veri setiyle iyi çalışmaz.
- Gürültülü verilere, eksik değerlere ve aykırı değerlere karşı duyarlıdır.
- Özellik ölçeklendirmeye ihtiyaç duyar.
- Doğru K değeri ile çalışır.
K-Ortalama Kümeleme Yöntemi

Avantajları;
- Büyük veri kümelerine ölçeklenir.
- Yakınsamayı garanti eder.
- Yeni örneklere kolayca uyum sağlar.
- Farklı şekil ve büyüklükteki kümelere genelleme yapar.
Dezavantajları;
- Aykırı değerlere duyarlıdır.
- k değerlerini manuel olarak seçmek zordur.
- Başlangıç değerlerine bağlıdır.
- Boyut arttıkça ölçeklenebilirlik (scalability) azalır.
Naive Bayes Sınıflandırıcısı
Avantajları;
- Eğitim süresi daha azdır.
- Kategorik girdiler için daha uygundur.
- Uygulaması kolaydır.
Dezavantajları;
- Tüm özelliklerin bağımsız olduğunu varsayar ancak bu gerçek hayatta nadirdir.
- Frekansı sıfırdır.
- Tahmin bazı durumlarda yanlış olabilir.
Bonus: Yapay Sinir Ağları (YSA)
Avantajları;
- Doğrusal olmayan modellerde karmaşık ilişkileri öğrenme becerisine sahiptir.
- Görülmemiş veriler üzerinde genelleme yapabilir.
Dezavantajları;
- Eğitim süresi uzundur.
- Yakınsamayı garanti edemez.
- Çözümü açıklamak zordur.
- Donanım gerektirir.
- Kullanıcının problemi çevirme becerisini gerektirir.