Makine öğrenimi, bilgisayarların veri setlerini kullanarak öğrenmesine izin veren bir yapay zeka alt alanıdır. Bu öğrenme, farklı türlerdeki algoritmalar kullanılarak gerçekleştirilir. Makine öğrenimi algoritmaları hakkında yazmaya başlayalım!
Makine Öğrenimi Algoritmaları
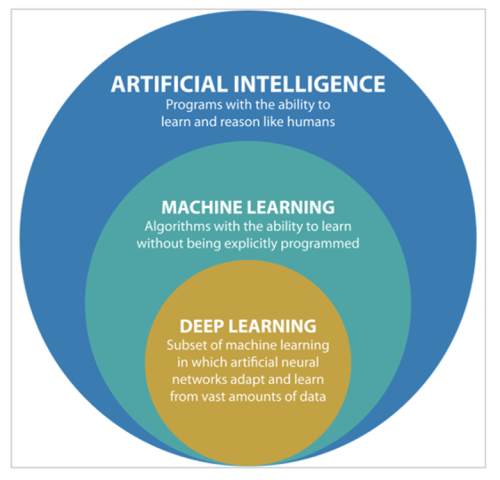
Makine öğrenimi, veri analizi ve yapay zeka gibi alanlarda kullanılan bir dizi algoritmadan oluşur. Makine öğrenimi algoritmaları, genellikle denetimli ve denetimsiz öğrenme olarak iki ana kategoriye ayrılır:
- Denetimli Öğrenme: Denetimli öğrenme, öğrenme verileri ve hedef çıktıları kullanarak modelin öğrenmesini sağlayan bir öğrenme yöntemidir. Bu yöntem, önceden etiketlenmiş verileri kullanarak doğru sonuçları tahmin etmeyi öğrenir. Denetimli öğrenme algoritmaları, öğrenme verilerindeki özelliklere dayanarak belirli bir çıktıya ulaşmak için kullanılan bir dizi matematiksel denklemin çözümlenmesi yoluyla çalışır. Örnek olarak, sınıflandırma ve regresyon algoritmaları denetimli öğrenme algoritmalarına örnek verilebilir. Sınıflandırma algoritmaları, öğrenme verilerindeki özellikleri kullanarak belirli bir sınıfa ait olup olmadığını tahmin etmek için kullanılır. Regresyon algoritmaları ise öğrenme verilerindeki özellikleri kullanarak bir çıktı değerini tahmin etmek için kullanılır.
- Denetimsiz Öğrenme: Denetimsiz öğrenme, verilerin yapılandırılmamış ve etiketlenmemiş olduğu durumlarda kullanılan bir öğrenme yöntemidir. Bu yöntem, önceden bilinmeyen özelliklerin belirlenmesine yardımcı olur. Denetimsiz öğrenme algoritmaları, veri setindeki yapısal olmayan desenleri veya grupları keşfetmek için kullanılır. Örnek olarak, kümeleme algoritmaları denetimsiz öğrenme algoritmalarına örnek verilebilir. Kümeleme algoritmaları, veri setindeki özellikleri kullanarak benzer özelliklere sahip verileri gruplandırır.
Denetimli ve denetimsiz öğrenme arasındaki temel fark, veri kümesindeki etiketlenmiş verilerin varlığıdır. Denetimli öğrenme algoritmaları, önceden etiketlenmiş verileri kullanarak doğru sonuçları tahmin etmeyi öğrenir. Denetimsiz öğrenme algoritmaları ise veri setindeki yapısal olmayan desenleri veya grupları keşfetmek için kullanılır.
Denetimli Öğrenme Algoritmaları:
Denetimli öğrenme algoritmaları, girdi ve çıktılar arasındaki ilişkiyi belirlemek için bir örnek veri kümesine dayalı olarak öğrenme yaparlar. Bu algoritmalar, bir örnek veri kümesindeki girdilerin özelliklerini ve hedef çıktıları (etiketleri) öğrenerek, daha sonra yeni girdiler için doğru çıktıları tahmin etmek için kullanılabilirler.
Denetimli öğrenme algoritmaları, iki ana kategoriye ayrılabilir: sınıflandırma ve regresyon. Sınıflandırma algoritmaları, bir girdiye karşılık gelen çıktıyı belirli bir sınıfa (kategoriye) atar. Örneğin, bir e-postanın spam veya değil spam olarak sınıflandırılması. Regresyon algoritmaları ise, bir girdiye karşılık gelen sürekli bir sayısal değer tahmin eder. Örneğin, bir evin fiyatını belirleyen faktörlerin kullanıldığı bir regresyon modeli.
En popüler denetimli öğrenme algoritmaları arasında şunlar bulunur:
- Lineer Regresyon
- Lojistik Regresyon
- Karar Ağaçları
- Rastgele Ormanlar
- Destek Vektör Makineleri
- Yapay Sinir Ağları
- Derin Öğrenme Yöntemleri
Bu algoritmaların her biri, farklı veri tipleri ve özellikleri için uygun olabilir. Örneğin, sınıflandırma problemleri için lojistik regresyon ve karar ağaçları sıklıkla kullanılırken, resim ve metin gibi karmaşık veri türleri için yapay sinir ağları ve derin öğrenme yöntemleri daha etkilidir.
Denetimsiz Öğrenme Algoritmaları:
Denetimsiz öğrenme algoritmaları, bir örnek veri kümesi kullanmadan, verilerin içindeki yapıları ve özellikleri öğrenmek için kullanılır. Bu algoritmalar, girdi verileri arasındaki benzerlikleri veya farklılıkları tespit ederek, veri setini birkaç farklı gruba ayırmak veya özellikleri çıkararak veri setinin boyutunu azaltmak gibi işlemleri gerçekleştirirler.
Denetimsiz öğrenme algoritmaları, genellikle sınıflandırma veya regresyon gibi doğrudan bir çıktı tahmini yapmak yerine, veriler arasındaki yapısal benzerlikleri veya özelliklerini keşfetmek için kullanılırlar. Bu algoritmalar, veri setinin daha iyi anlaşılmasına yardımcı olabilir ve daha sonra denetimli öğrenme algoritmalarında kullanılacak özellikleri belirlemeye yardımcı olabilir.
En popüler denetimsiz öğrenme algoritmaları şunlardır:
- Kümeleme (Clustering): Benzer özelliklere sahip girdileri bir araya getirerek verileri gruplara ayırır. Bu algoritmalardan bazıları; K-Means, Hiyerarşik Kümeleme, ve DBSCAN’dir.
- Boyut Azaltma (Dimensionality Reduction): Yüksek boyutlu verileri daha düşük boyutlu verilere dönüştürür ve böylece veri işleme süresini azaltır. Bu algoritmaların bazıları; Principal Component Analysis (PCA), t-SNE ve Autoencoder’dir.
- Birlikte Öğrenme (Association Learning): Veri setindeki öğeler arasındaki ilişkileri tespit eder. Örnek algoritmalar arasında; Apriori ve FP-Growth yer alır.
- Gelişigüzel Ağlar (Boltzmann Machines): Birbirleriyle bağlantılı bir dizi birimden oluşan yapay sinir ağı, veriler arasındaki yapısal benzerlikleri veya özelliklerini keşfetmek için kullanılır.
Bu algoritmaların her biri, farklı veri tipleri ve özellikleri için uygun olabilir. Örneğin, boyut azaltma teknikleri, görüntü işleme gibi yüksek boyutlu veriler için kullanılırken, kümeleme algoritmaları, pazarlama analizi veya sosyal ağ analizi gibi veri gruplarındaki benzerlikleri keşfetmek için kullanılabilir.
Sonuç olarak, makine öğrenmesi algoritmaları, birçok farklı uygulama alanında kullanılan etkili araçlardır. Bu algoritmalar, büyük veri setlerini analiz etmek ve öngörü modelleri oluşturmak için kullanılır. Bu sayede, işletmelerin daha verimli ve doğru kararlar almasına yardımcı olur. Ancak, hangi algoritmanın kullanılacağına karar verirken veri setinin özellikleri, analiz edilecek sorunun doğası ve uygulama alanı gibi faktörler dikkate alınmalıdır. Ayrıca, algoritmanın doğru şekilde uygulanması da sonuçların kalitesini etkileyebilir. Makine öğrenmesi alanındaki gelişmelerin devam etmesiyle birlikte, bu algoritmaların daha da yaygın bir şekilde kullanılması ve yeni uygulama alanlarının keşfedilmesi beklenmektedir.